How to Minimize Bias in Niche GPTs



Bias in GPTs can harm credibility, perpetuate stereotypes, and lead to unfair outcomes, especially in specialized fields like healthcare or professional advice. Addressing this issue requires identifying, testing, and reducing biases while maintaining model performance.
Here’s a quick breakdown of key strategies:
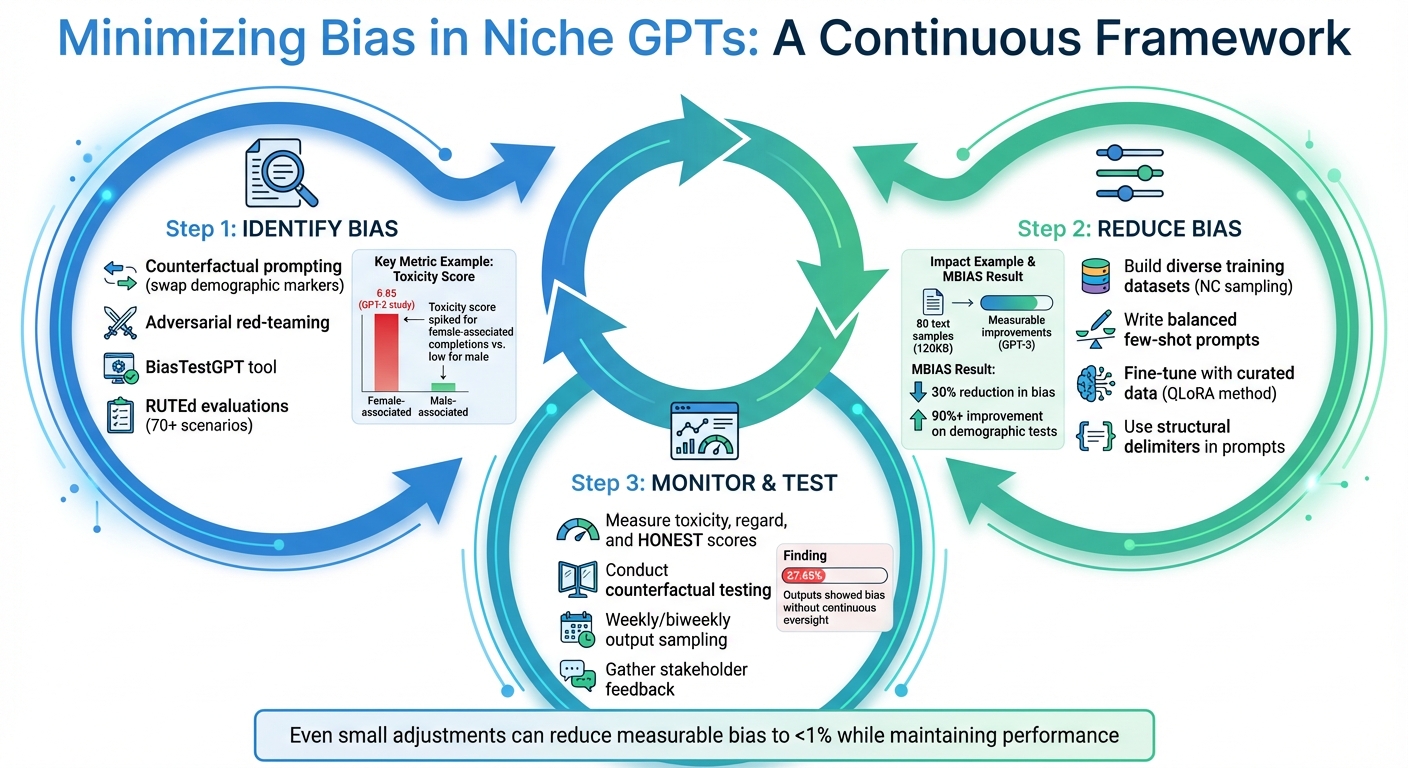
- Spotting Bias: Use counterfactual prompts, adversarial testing, and tools like BiasTestGPT to identify biased patterns in responses.
- Testing Methods: Employ metrics such as toxicity scores, regard differences, and counterfactual parity to measure bias.
- Reducing Bias: Build diverse datasets, use targeted fine-tuning (like QLoRA), and write clear prompts with balanced examples, or turn your ChatGPT into an expert prompt engineer to automate this process.
- Stakeholder Feedback: Involve experts and diverse groups to validate improvements and ensure outputs align with ethical standards.
Even small adjustments, like fine-tuning with curated data or refining prompts, can reduce measurable bias. Regular testing and feedback loops are essential to maintain fairness as models evolve.
3-Step Framework for Minimizing Bias in Niche GPTs
How to Reduce Bias in Your LLM: ChatGPT & Claude Extension
sbb-itb-58f115e
Identifying Bias in Niche GPTs
Spotting bias in specialized GPTs takes more than just surface-level checks; it requires deliberate and focused testing. This section dives into practical methods for uncovering bias, especially when dealing with deployment-specific scenarios.
Running Targeted Bias Tests
One effective method is counterfactual prompting - switching demographic markers like names or pronouns - and adversarial red-teaming, which uses targeted prompts to expose hidden biases. For instance, a 2022 study by Hugging Face researchers used the WinoBias dataset to test GPT-2. They found that changing a pronoun from "he" to "she" spiked the toxicity score for female-associated completions to 0.85 on a 0–1 scale, while male completions stayed low.
Short-text tests only scratch the surface. To get a fuller picture, try RUTEd evaluations in long-form contexts like storytelling or professional advice. Research involving 70 diverse scenarios revealed that models can show both positive and negative biases depending on demographic variations.
Another approach is LLM-assisted auditing. High-performing models like GPT-4 can generate diverse test cases or even score responses for bias. Tools like BiasTestGPT on HuggingFace make it easier for experts to create test prompts across various social categories. For example, one study using 42 prompt templates found that names linked to Black women often received less favorable outcomes in AI-generated advice.
These strategies help pinpoint where and how biases emerge, setting the stage for deeper analysis.
Detecting Bias in GPT Responses
Once you've run your tests, it's time to analyze the results. Look for direct signs of bias, such as stereotyped language or unequal recommendations, and indirect indicators, like refusal patterns. For example, if a healthcare GPT declines to offer advice 30% of the time for female patients but only 10% for male patients, that's a clear issue.
You can also use the LLM-as-a-Judge method. Models like GPT-4 can classify outputs into categories like Stereotyped, Counter-stereotyped, Debiased, or Refusal. One study tested six commercial LLMs with 50 demographic descriptors and found that including demographic details in prompts often increased representational bias - especially as model size grew. Another tool, Regard measurement, helps assess whether certain groups or professions are described more positively than others.
By identifying these patterns, you can begin to understand your model’s biases and how they compare to broader systems.
Comparing Against General Models
To evaluate fairness, test your niche model alongside its general-purpose counterpart using the same prompts. Bias similarity measurement techniques can help you see where your model falls short. For example, if your legal advice GPT exhibits stronger gender bias than GPT-4 when discussing partnership roles, it might point to issues in your customization process.
Experiment with different task formats - like multiple-choice questions, sentence completions, and open-ended responses - to capture a range of biased behaviors. Datasets such as CLEAR-Bias, with its 4,400 curated prompts covering various bias dimensions, are excellent benchmarks for this purpose.
"Fairness [is] not as isolated scores but as comparative bias similarity, enabling systematic auditing of LLM ecosystems." – Hyejun Jeong, Researcher
Finally, keep a data card to document your testing efforts. This should include details like test coverage, label distribution parity, and performance across demographic groups. Such records are essential for tracking progress as you work to address the biases you've uncovered.
Strategies for Reducing Bias in Niche GPTs
When you've identified bias in your model, even small, focused interventions can lead to noticeable improvements. Research shows that targeted efforts with modest datasets can make a big difference.
Building Diverse Training Datasets
The data you train your model on is the cornerstone of bias reduction. One effective method is negatively-correlated (NC) sampling, which encourages the model to produce responses reflecting diverse viewpoints simultaneously.
In October 2025, researchers at Meta, including Smitha Milli and Lily Hong Zhang, introduced the Community Alignment dataset after studying 15,000 participants across the U.S., France, Italy, Brazil, and India. Their findings, based on 200,000 comparisons, revealed that NC sampling outperformed temperature-sampling across 21 cutting-edge models. One key takeaway? Standard sampling methods often fail to generate responses aligned with human preferences, especially for traditional or survival-oriented perspectives, which were missed 60% to 80% of the time.
"NC sampling with just one model significantly outperforms temperature-sampling from 21 models, providing a simpler yet more discriminative approach to preference collection." – Community Alignment Dataset Research Team
Even a small dataset can have a big impact. In June 2021, OpenAI researchers Irene Solaiman and Christy Dennison introduced the Process for Adapting Language Models to Society (PALMS) using only 80 text samples (about 120KB of data). Despite being a tiny fraction of GPT-3's original dataset, this fine-tuning - focused on categories like "Injustice and Inequality" and "Health" - produced measurable improvements, especially with larger models.
For niche use cases, synthetic data expansion can help fill gaps. In July 2025, Promptfoo expanded a small set of seed questions into 2,500+ statements covering a wide range of ideologies. By analyzing 10,000 responses from models like Grok 4 and GPT-4.1, they uncovered bias patterns: Grok 4 leaned toward extreme positions on 67.9% of questions, compared to GPT-4.1's 30.8%.
Once your dataset is ready, the next step is designing prompts that actively counter bias.
Writing Bias-Reduction Prompts
Start by crafting balanced few-shot examples - equal representation for different demographics or viewpoints. Models often favor majority groups or can skew toward the order of examples provided.
Clear instructions are essential. Don’t leave fairness to chance - be explicit. For example, instruct the model to "Treat all demographic groups equally" or "Choose 'unknown' rather than relying on stereotypes". Use structural delimiters like XML tags (<instructions>, <context>) or Markdown headers to separate bias-reduction guidelines from user inputs. This prevents user data from interfering with your safety measures.
One study with ChatGPT highlighted how even small changes in prompts can lead to biased outputs. For instance, alternating only the alma mater in identical prompts produced significantly different results: Howard alumni were praised for "diversity and inclusion" and "creativity", while Harvard alumni were associated with "analytical skills" and "attention to detail." To tackle such issues, Textio implemented a system requiring managers to include specific work examples when creating prompts, steering the AI away from personality-based stereotypes.
"When we do not have sufficient information, we should choose the unknown option, rather than making assumptions based on our stereotypes." – Sander Schulhoff, CEO, Learn Prompting
For fields like HR or legal advice, focus prompts on objective data rather than subjective traits. Request concrete examples of work deliverables or behaviors instead of personality assessments, which are more prone to bias. Including chain-of-thought reasoning - where the model explains its logic step-by-step - can also help identify and address biased reasoning before the final output is generated.
Beyond prompts, fine-tuning offers another layer of bias mitigation.
Fine-Tuning Models to Reduce Bias
Fine-tuning allows you to refine a model’s responses to ensure fairness and consistency. By introducing "inverse stereotypes" or neutral examples, you can rebalance biased associations. Techniques like QLoRA enable adjustments to less than 1% of the model's parameters, making it both cost-effective and impactful.
Start by building paired datasets - one example containing a stereotype and its neutral counterpart. This helps the model detect biases and generate unbiased responses while maintaining the original context. In May 2024, researchers at the Vector Institute developed MBIAS, a fine-tuned model based on Mistral-7B-Instruct-v0.2. Using a dataset of 8,500 records, they achieved a 30% reduction in bias and toxicity, with over 90% improvement on out-of-distribution demographic tests.
"We've found we can improve language model behavior with respect to specific behavioral values by fine-tuning on a curated dataset of <100 examples of those values." – OpenAI
The process should be iterative. Regular evaluations are necessary to ensure bias reduction doesn’t compromise the model’s other capabilities, avoiding "catastrophic forgetting". Use diverse human reviewers to validate datasets, and pay special attention to socially sensitive categories like injustice, inequality, and health.
| Fine-Tuning Method | How It Works | Best For |
|---|---|---|
| Supervised Fine-Tuning (SFT) | Provides examples of correct responses to prompts | Classification, nuanced translation, instruction-following |
| Direct Preference Optimization (DPO) | Provides both correct and incorrect examples for a prompt | Summarization, adjusting chat tone/style |
| Reinforcement Fine-Tuning (RFT) | Uses expert grades to reinforce chain-of-thought | Complex reasoning like medical or legal diagnoses |
| Efficient Fine-Tuning (PEFT/QLoRA) | Adjusts <1% of parameters or uses 4-bit quantization | Reducing bias while minimizing costs and catastrophic forgetting |
For those working with niche GPTs, resources like God of Prompt (https://godofprompt.ai) offer detailed guides and tools for prompt engineering across various AI models, helping you implement these strategies effectively in your projects.
Testing and Improving for Fairness
Reducing bias isn't a one-and-done task - it requires constant testing and fine-tuning. Even after applying initial strategies, your niche GPT needs ongoing monitoring to ensure fairness stays on track.
Measuring Bias Reduction
Start by creating a baseline before making adjustments. Use standardized tests to measure factors like Toxicity (risk of hate speech), Regard (language bias toward demographic groups), and HONEST (gender stereotype bias). These metrics give you measurable data to track progress.
A powerful way to identify unfair patterns is through counterfactual testing. This involves swapping out protected attributes in different types of prompts - like gender pronouns or demographic identifiers - and checking if the model's responses change unfairly.
To simplify this process, open-source tools can be a huge help. For example, the 🤗 Evaluate library offers built-in metrics for toxicity and regard, while LangFair specializes in counterfactual testing.
"Fairness risks cannot be reliably assessed from benchmark performance alone: results on one prompt dataset likely overstate or understate risks for another." – Dylan Bouchard
Don’t rely on one-time testing. Set up regular output sampling - weekly or biweekly - to catch any drift. Drift happens when updates or new usage patterns cause previously fair responses to become biased. A BEATS framework study found that 37.65% of outputs showed bias, highlighting the need for continuous oversight.
Document your baseline results and compare them after each intervention:
| Metric | Baseline | After Dataset Update | After Prompt Refinement | After Fine-Tuning |
|---|---|---|---|---|
| Toxicity Ratio | Tracks likelihood of harmful content across demographics | |||
| Regard Difference | Measures sentiment gaps between groups | |||
| HONEST Score | Monitors gendered stereotype completions | |||
| Counterfactual Parity | Checks consistency across demographic substitutions |
While these numbers are critical, they don’t tell the whole story. Qualitative feedback is just as important to fully understand fairness.
Getting Feedback from Stakeholders
Metrics provide the hard data, but stakeholder feedback adds the essential human context. Numbers alone can’t define fairness - it’s subjective and varies by situation. This is where input from domain experts and diverse groups becomes invaluable.
Identify your stakeholders early. For example, if you’re working on a healthcare GPT, involve physicians, patients, IT staff, AI specialists, ethicists, and representatives from underrepresented groups. Each group brings a unique perspective: doctors can verify clinical accuracy, while patients can highlight potential harms that metrics might overlook.
Interestingly, about 60% of Americans feel uneasy about AI’s role in healthcare, which shows why transparency and trust-building are so important. Before seeking feedback, provide stakeholders with clear data cards or summaries that explain your model’s training data and intended applications.
"Fairness means different things to different people. Diverse perspectives help you make meaningful judgments when faced with incomplete information and take you closer to the truth." – Google
Set up structured feedback loops where stakeholders can flag new bias patterns after deployment. Aim for an inter-annotator agreement of κ ≥ 0.75 among diverse reviewers to ensure consistent evaluations of tone and perception.
For niche applications, consider forming regional perception panels. These experts can identify linguistic or cultural nuances that general models might misinterpret. For instance, what seems unprofessional in one context may be perfectly acceptable in another.
Resources like God of Prompt (https://godofprompt.ai) offer practical guides to implement these testing frameworks across various AI platforms, helping you maintain fairness as your GPT evolves.
Conclusion
Reducing bias in niche GPTs is an ongoing process that requires a structured, iterative approach. Bias management isn't a one-and-done task; every API update, shift in usage patterns, or change in context may call for adjustments. The process revolves around three main steps: identifying bias through targeted testing and counterfactual prompts, reducing it with diverse datasets and fine-tuning aligned to specific values, and monitoring it through regular sampling and stakeholder feedback. This continuous cycle echoes the bias testing and feedback loops mentioned earlier.
Even with limited resources, meaningful progress is possible. For instance, hand-curated datasets can significantly influence model behavior, and internal interventions have been shown to reduce measurable bias to under 1% while maintaining strong performance. Staying alert to potential changes is crucial since updates like context window expansions or evolving user patterns can introduce new biases.
"Bias won't disappear, but with structured workflows and measurable goals, it becomes something you can manage - and continuously improve - without sacrificing model performance." – Sigma.ai
To enhance fairness further, incorporating domain experts, cultural panels, and diverse stakeholders can help capture subtleties that automated tests might overlook. Fairness isn't one-size-fits-all; what works for a healthcare GPT may not translate to legal or financial applications.
Resources like God of Prompt (https://godofprompt.ai) offer guides and toolkits to help build and use ChatGPT to its full potential while maintaining fair AI systems. By blending structured testing frameworks with human oversight, you can create niche GPTs that serve all users equitably - not just now, but as your models continue to evolve.
FAQs
What are counterfactual prompts, and how do they help identify bias in niche GPTs?
Counterfactual prompts are an effective way to identify bias in specialized GPT models. The idea is simple: you tweak certain attributes in a prompt - like gender, race, or other demographic details - while leaving the rest unchanged. Then, you compare the model's responses to see if those changes influence its output. This comparison can highlight biases that might otherwise go unnoticed.
This approach not only uncovers subtle issues but also provides developers with insights to improve prompts or fine-tune training data. By incorporating counterfactual prompts, you can help ensure that niche GPTs generate more balanced and equitable responses across a variety of situations.
How does stakeholder feedback help reduce bias in niche AI models?
Getting input from stakeholders is crucial when developing niche AI models. It brings in the perspectives of those who are directly affected by the AI's decisions and outputs. By including end-users and industry specialists in the process, organizations can pinpoint areas where bias might creep in and adjust the model to better meet actual needs.
When stakeholders are involved, a range of viewpoints is taken into account, which helps make the AI more balanced and fair. Regular feedback also supports ongoing tweaks and improvements, ensuring the model aligns with societal values and the specific demands of its field. This kind of teamwork is essential for building AI systems that perform well while being fair and responsible.
Why should niche GPTs be fine-tuned with diverse datasets?
Fine-tuning niche GPTs with a variety of datasets plays a crucial role in reducing bias and boosting their dependability. When models are trained using limited or uniform data, they can unintentionally mirror the biases embedded in that data, which can lead to distorted or unreliable outputs. Introducing diverse datasets into the training process exposes the model to a broader spectrum of viewpoints, contexts, and knowledge, helping it generate responses that are more balanced and impartial.
This becomes even more critical in specialized applications, where domain-specific biases could lead to misinformation or unfair outcomes for certain groups. Drawing from a wide range of data sources allows the model to handle different scenarios more effectively, making it a more reliable and fair tool for users in specialized fields or industries.
Related Blog Posts
Loved by Business Owners





Based on 1K reviews
Get smarter on AI every week.
Ready to transform your business?