How fast does your AI model respond? For many applications, latency is the deciding factor. This article compares the response times of leading large language models (LLMs) across key metrics and use cases. The focus is on two critical latency measures:
- Time to First Token (TTFT): How quickly the model starts responding after receiving input.
- Per-Token Latency (PTL): The speed at which the model generates tokens after the initial response.
Key Findings:
- Mistral Large 2512 is the fastest for real-time tasks like live chat, with a TTFT of 0.30 seconds.
- GPT-5.2 balances speed and sustained output, excelling in content generation and analysis.
- Claude 4.5 Sonnet is slower (2.0 seconds TTFT) but reliable for batch tasks like reporting.
- Grok 4.1 Fast Reasoning has a slow start (up to 11 seconds) but generates tokens extremely fast (0.005 seconds PTL), ideal for large-scale processing.
- DeepSeek V3.2 is cost-effective but slow, with TTFTs ranging from 7 to 19 seconds.
Why It Matters:
Fast response times make AI applications feel smooth and natural. For customer support, fast TTFT ensures seamless interactions. In contrast, batch tasks like coding or data analysis benefit more from low PTL for faster overall completion.
Quick Tip: Using expert prompt engineering to create shorter prompts can improve latency across all models.
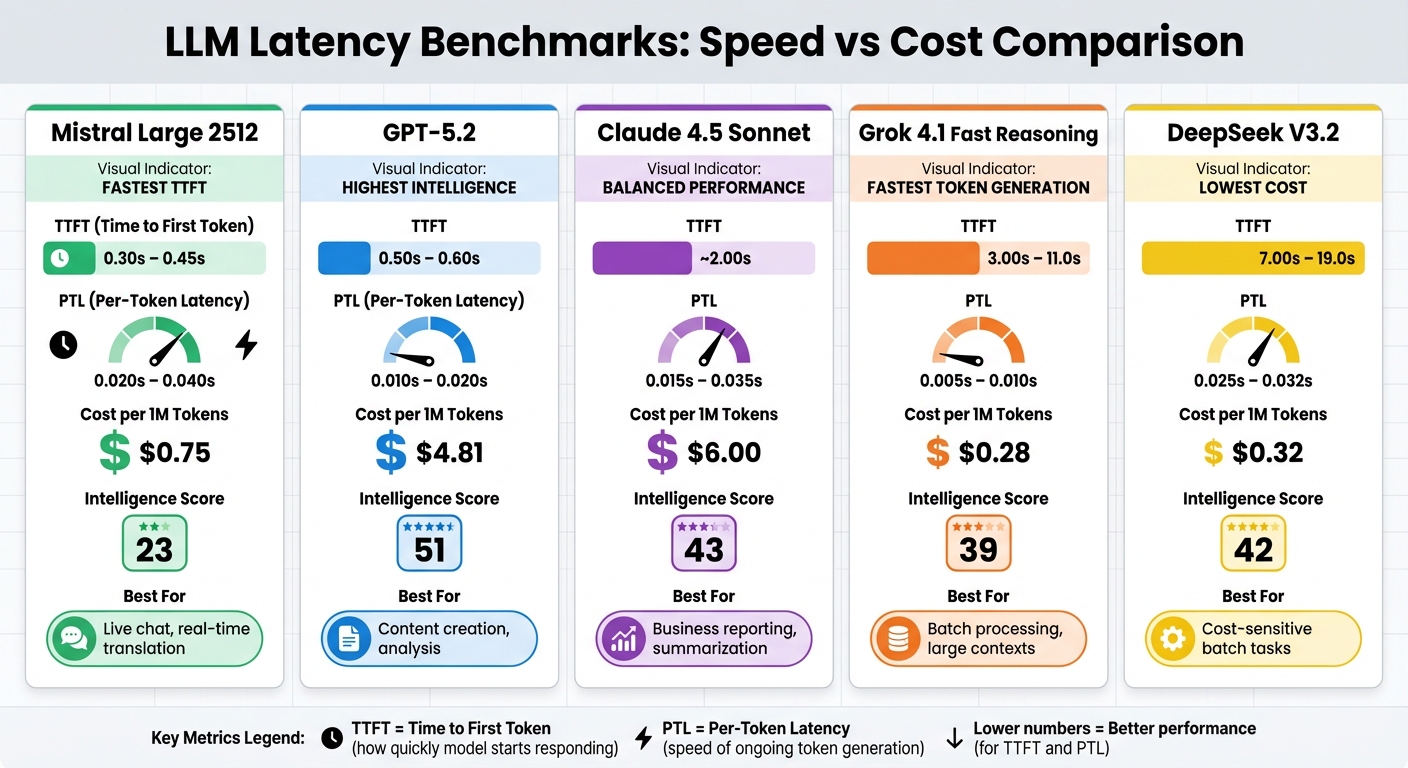
Quick Comparison
| Model | TTFT (Range) | PTL (Range) | Cost per 1M Tokens | Best Use Case |
|---|---|---|---|---|
| Mistral Large 2512 | 0.30s – 0.45s | 0.020s – 0.040s | $0.75 | Live chat, real-time translation |
| GPT-5.2 | 0.50s – 0.60s | 0.010s – 0.020s | $4.81 | Content creation, analysis |
| Claude 4.5 Sonnet | ~2.00s | 0.015s – 0.035s | $6.00 | Business reporting, summarization |
| Grok 4.1 | 3.00s – 11.0s | 0.005s – 0.010s | $0.28 | Batch processing, large contexts |
| DeepSeek V3.2 | 7.00s – 19.0s | 0.025s – 0.032s | $0.32 | Cost-sensitive batch tasks |
Choosing the right model depends on your priorities: speed, cost, or task complexity.
LLM Latency Comparison: Response Times and Costs Across 5 Leading AI Models
1. Mistral Large 2512
Time to First Token (TTFT)
Mistral Large 2512 stands out with consistently fast TTFT across various tasks, keeping response times under a second. For Q&A and coding tasks, it achieves a TTFT of 0.30 seconds, while language translation and business analysis take 0.40 seconds, and summary generation completes in 0.45 seconds.
In Q&A scenarios, Mistral responds in 0.30 seconds, outpacing GPT-5.2 at 0.60 seconds and Claude 4.5 Sonnet at 2.0 seconds. This speed advantage extends to coding tasks, where Mistral maintains its 0.30-second start time, compared to Grok 4.1’s 11 seconds, which is delayed by additional internal reasoning processes. Next, we’ll look at how the model performs during ongoing token generation.
Per-Token Latency
While Mistral’s initial response times are impressive, assessing its per-token latency (PTL) reveals how it handles sustained output. The model’s PTL varies by task, ranging from 0.020 seconds for translation to 0.040 seconds for business analysis. For customer support applications, it achieves a reliable 0.025-second PTL, ensuring smooth and responsive interactions with optimized workflows.
For longer outputs, differences in PTL become more noticeable. GPT-5.2 matches Mistral’s 0.020-second PTL in Q&A tasks, while Grok 4.1 Fast Reasoning boasts speeds as low as 0.005 seconds for coding once generation begins. This suggests that for extended outputs, models with lower PTL can compensate for slower initial responses.
Suitability by Use Case
Mistral Large 2512 is particularly effective in scenarios where fast initial responses are critical:
- Live customer support systems benefit from its 0.30-second Q&A start time, ensuring quick and natural interactions.
- Real-time translation services take advantage of the 0.40-second start time combined with the model’s fastest PTL of 0.020 seconds.
- Interactive coding assistants and IDE integrations gain from the 0.30-second TTFT, providing immediate feedback during development.
For business analysis and dashboard generation, the 0.40-second TTFT and 0.040-second PTL make it ideal for live reporting and short summaries within automated business workflows. Similarly, summary generation tasks are well-supported with a 0.45-second start time, making it suitable for time-sensitive document processing.
These latency metrics, paired with competitive pricing, position Mistral Large 2512 as a strong choice for real-time applications. The model is available under an Apache 2.0 license and costs $0.50 per million input tokens and $1.50 per million output tokens, resulting in an approximate blended rate of $0.75 per million tokens. This combination of performance and affordability makes it a compelling option for businesses focused on responsiveness and efficiency.
sbb-itb-58f115e
2. GPT-5.2
Time to First Token (TTFT)
GPT-5.2 boasts an impressive sub-second Time to First Token (TTFT), ranging from 0.50 to 0.60 seconds. For specific tasks like coding and business analysis, TTFT averages 0.50 seconds, while language translation comes in at 0.55 seconds, and Q&A or summary generation clocks in at 0.60 seconds. Across 238 automated benchmark tests, the model achieved an average TTFT of 980 milliseconds.
In December 2025, Box integrated GPT-5.2 for complex document extraction. The result? Processing times dropped from 46 seconds to just 12 seconds – a 74% reduction. This allowed for real-time analysis of documents. As Sebastian Crossa, Co-Founder of LLM Stats, explained:
"A 46-second wait breaks user flow; a 12-second wait is tolerable for complex tasks. This shifts the boundary of what you can build with synchronous API calls."
However, the model’s performance isn’t without variability. Its throughput ranges widely, with a coefficient of variation at 129.5%, producing speeds between 7.66 and 43.40 tokens per second. For developers, this means implementing strong error-handling mechanisms to manage such fluctuations effectively.
Per-Token Latency
Where GPT-5.2 truly shines is in its sustained generation speed. Its per-token latency (PTL) ranges from 0.010 seconds (for translation tasks) to 0.020 seconds (for Q&A, summaries, and business analysis). While the model starts slower, this low PTL ensures it excels in longer outputs, ultimately outperforming Mistral in long-form content generation.
For language translation, GPT-5.2 achieves its fastest sustained speed at 0.010 seconds per token, while coding tasks operate at 0.015 seconds per token. On average, the model streams at 27.60 tokens per second. In practice, this translates to a dramatic improvement in analytical queries, with response times dropping from 19 seconds (GPT-5) to just 7 seconds in GPT-5.2 – a 63% speed boost.
Suitability by Use Case
These performance upgrades make GPT-5.2 a versatile tool for a wide range of applications.
For tasks requiring a balance between quick initial responses and efficient sustained generation, GPT-5.2 delivers. For instance, Harvey, a legal AI platform, leveraged the model’s 400,000-token context window in December 2025 to analyze entire case files without splitting them into chunks. This reduced hallucinations and enabled thorough legal research workflows.
The model comes in three variants tailored to different needs:
- Instant: Prioritizes speed for tasks like customer support prompts.
- Thinking: Allows for configurable reasoning depth.
- Pro: Focuses on maximum accuracy, albeit with higher latency.
For business analysis and real-time dashboards, the combination of a 0.50-second TTFT and 0.020-second PTL enables live reporting that previously required asynchronous solutions.
Pricing starts at $1.75 per million input tokens and $14.00 per million output tokens. For repetitive system prompts, cached inputs are available at $0.175 per million tokens – a 90% discount. Additionally, the Batch API offers a 50% discount for tasks that don’t require real-time processing.
3. Claude 4.5 Sonnet
Time to First Token (TTFT)
Claude 4.5 Sonnet has an average TTFT of 2.0 seconds across standard tasks. While this is slower than Mistral Large 2512 and GPT-5.2, it still outpaces DeepSeek V3.2, which averages 7.0 seconds.
Performance also depends on the API provider. Google Vertex offers the fastest TTFT at 0.88 seconds, while Databricks takes 1.94 seconds, making it more than twice as slow. For applications where speed is critical, selecting the right provider can make a noticeable difference. Across 1,189 benchmark tests, the Claude 4 fleet averaged a TTFT of 1,312 milliseconds. Next, let’s look at how the model performs during continuous token generation.
Per-Token Latency
Once the initial delay is out of the way, Claude 4.5 Sonnet delivers steady token generation speeds, ranging from 0.015 seconds per token for translation tasks to 0.035 seconds for business analysis. This consistency ensures a smooth flow of responses after the process begins.
Token generation speeds also vary by provider. Amazon Bedrock leads with an impressive 93.3 tokens per second, while Google Vertex produces 48.0 tokens per second. These differences can significantly affect job completion times for tasks like document summarization or batch data processing. These efficiencies are central to optimizing AI workflows for enterprise scale. Pricing, however, remains steady at $6.00 per million tokens for most providers, with Databricks charging $8.25.
Suitability by Use Case
Claude 4.5 Sonnet’s latency characteristics make it particularly effective in certain scenarios. For language translation, the combination of a 2-second TTFT and a 0.015-second per-token latency enables efficient handling of long-form translations. It also shines in summarization and editing tasks, where batch processing is more important than immediate feedback.
For customer support, the 2-second initial delay is close to the upper limit of what feels natural in live interactions. As Kwindla Hultman Kramer, CEO of Daily, explained:
"Natural conversation requires voice-to-voice response times under 1,500ms".
While Claude 4.5 Sonnet’s TTFT slightly exceeds this benchmark, its steady token generation ensures a professional and conversational flow once responses begin. For business analysis and scheduled reporting – tasks where accuracy and throughput matter more than instant responses – the model performs reliably.
Additionally, the model includes an "Extended Thinking" mode for handling complex reasoning tasks. However, this mode comes with significantly longer processing times, sometimes stretching to minutes. For most users, the standard mode strikes a good balance between speed and capability, aligning with earlier performance benchmarks.
4. Grok 4.1 Fast Reasoning
Time to First Token (TTFT)
Released by xAI in November 2025, Grok 4.1 Fast Reasoning introduces a "slow start, fast finish" design. This means it spends more time on internal reasoning before producing output, leading to longer TTFTs.
Here’s how TTFT varies by task:
- Q&A: 3.0 seconds
- business analysis and summary generation: 4.0 seconds
- Translation: 6.0 seconds
- Coding: 11.0 seconds
The median TTFT for the model is 11.39 seconds. For comparison, Mistral Large 2512 and GPT-5.2 have much faster TTFTs at 0.30 and 0.60 seconds respectively, while DeepSeek V3.2 starts at 7.0 seconds. Grok 4.1’s slower initial response is a trade-off for its deeper reasoning capabilities.
Per-Token Latency
Once Grok 4.1 begins generating output, its performance is impressive. It achieves 0.005 seconds per token for tasks like coding and language translation, making it three times faster than GPT-5.2 and six times faster than DeepSeek V3.2 during sustained output. For tasks such as Q&A, business analysis, and summary generation, the per-token latency is slightly higher at 0.010 seconds.
The model can generate at a speed of 153.9 tokens per second, completing a 500-token response in approximately 14.64 seconds, including the initial reasoning time. At a cost of $0.28 per million tokens (based on a 3:1 input/output ratio), it offers cost-effective performance for high-throughput tasks.
Suitability by Use Case
Grok 4.1 shines in scenarios where total completion time is more important than instant responses. For example:
- Batch code generation: The 11-second startup delay is negligible when producing thousands of lines of code, and the 0.005-second per-token speed ensures quick completion.
- Long-form translation projects: Its ultra-fast generation rate makes it ideal for handling extensive translation tasks.
- Comprehensive business reports and data analysis: With a 4-second TTFT and 0.010-second per-token latency, it delivers detailed insights efficiently.
Cem Dilmegani, Principal Analyst at AIMultiple, highlighted this balance:
"Grok 4.1 Fast Reasoning showed a higher Time To First Token compared to simpler generative models because it spends more time reasoning internally. Despite the slower start, the quality and precision of its answers were significantly better".
For real-time applications, the 3-second delay in tasks like Q&A might disrupt the user experience. However, using typing indicators can help manage user expectations. Additionally, Grok 4.1 offers a 3x reduction in hallucinations compared to earlier versions, making it a reliable choice for critical applications.
These factors set Grok 4.1 apart as a model that prioritizes thoughtful, high-quality output over immediate response times. Its strengths will be further analyzed in the Pros and Cons section.
5. DeepSeek V3.2

Time to First Token (TTFT)
DeepSeek V3.2, a Mixture-of-Experts model (685B total, 37B active per token), operates in two modes: standard and reasoning. While reasoning mode enhances analytical capabilities, it significantly increases latency.
In reasoning mode, DeepSeek V3.2 records the slowest TTFT among current large language models. For Q&A tasks, the first token takes 7.0 seconds to appear. Summary generation and language translation both take 7.5 seconds, while business analysis requires 8.0 seconds. The delay is most pronounced in coding tasks, with a TTFT of 19.0 seconds.
Switching to non-reasoning mode significantly improves TTFT. On Google Vertex, it drops to 0.47 seconds, while DeepInfra delivers 0.76 seconds. The official DeepSeek API, however, reports a slightly slower 1.13 seconds in this mode. These differences underscore the importance of choosing the right mode for your workflow based on the task at hand, as noted in earlier benchmarks.
Per-Token Latency
Once generation begins, DeepSeek V3.2 maintains consistent speeds across tasks. Q&A tasks show the slowest per-token latency at 0.032 seconds, while summary generation and language translation are faster at 0.025 seconds per token. Business analysis and coding tasks fall in between at 0.030 seconds per token.
When compared to its peers, DeepSeek V3.2 lags behind. GPT-5.2 achieves a faster 0.020 seconds, and Grok 4.1 outpaces both with 0.010 seconds. The disparity is even more striking in coding tasks, where Grok 4.1’s 0.005 seconds per token makes it six times faster than DeepSeek V3.2.
Suitability by Use Case
DeepSeek V3.2 shines in scenarios where speed isn’t the priority. Its 128K token context and 39.2% AIME 2024 accuracy make it a strong choice for tasks like in-depth document analysis and processing lengthy texts. The model’s strengths align with batch processing and workflow optimization for analytical tasks rather than real-time applications.
However, it’s not well-suited for speed-sensitive use cases like live customer support or interactive coding environments. As AIMultiple highlights:
"DeepSeek V3.2… is the slowest model overall. The significant wait before the first token makes it less suitable for speed-critical Q&A systems".
The 19-second delay in coding tasks is particularly disruptive for users relying on real-time feedback in IDEs.
For teams focused on cost efficiency, DeepSeek V3.2 offers competitive pricing at $0.29–$0.32 per million tokens, with context caching reducing costs to $0.014 per million tokens for cache hits. This makes it a practical option for batch processing large reports or summarizing extensive documents, where a 7–8 second TTFT is acceptable.
Exploring the Latency/Throughput & Cost Space for LLM Inference // Timothée Lacroix // CTO Mistral
Pros and Cons
When selecting the ideal language model, it’s all about finding the right balance between speed, intelligence, and cost. Here’s a closer look at how each model stacks up, drawing from the earlier performance metrics.
Mistral Large 2512 stands out for its quick response time, with a TTFT of just 0.30 seconds and an intelligence score of 23. This makes it a great choice for tasks like live customer support or real-time translation, where speed is critical.
GPT-5.2 is a powerhouse for complex tasks. With an intelligence score of 51 and per-token speeds ranging from 0.010 to 0.020 seconds, it’s well-suited for content creation and interactive coding. However, this performance comes at a cost – $4.81 per million tokens, which is significantly higher than some alternatives like DeepSeek V3.2.
Grok 4.1 Fast Reasoning offers an interesting tradeoff. It has a slower start, with initial responses taking up to 11 seconds for coding tasks due to its chain-of-thought processing. But once it gets going, it generates tokens at an impressive 0.005 seconds per token. This model shines in batch processing scenarios where the initial delay doesn’t disrupt the workflow.
Claude 4.5 Sonnet delivers consistent and predictable performance, with a TTFT of 2 seconds and an intelligence score of 43. These qualities make it a dependable option for tasks like scheduled reporting and business analysis. On the other hand, DeepSeek V3.2 matches Claude’s intelligence score (42) but comes at a fraction of the cost – $0.32 per million tokens. Its longer TTFT makes it better suited for applications where cost efficiency outweighs the need for speed.
| Model | TTFT (Range) | Per-Token Latency | Intelligence Score | Price per 1M Tokens | Ideal Use Case |
|---|---|---|---|---|---|
| Mistral Large 2512 | 0.30s – 0.45s | 0.020s – 0.040s | 23 | N/A | Live customer support, real-time translation |
| GPT-5.2 | 0.50s – 0.60s | 0.010s – 0.020s | 51 | $4.81 | Content generation, interactive coding |
| Claude 4.5 Sonnet | ~2.00s | 0.015s – 0.035s | 43 | $6.00 | Business analysis, scheduled reporting |
| Grok 4.1 Fast Reasoning | 3.00s – 11.0s | 0.005s – 0.010s | 39 | $0.28 | Batch processing, large context analysis |
| DeepSeek V3.2 | 7.00s – 19.0s | 0.025s – 0.032s | 42 | $0.32 | Applications tolerating delay, cost efficiency |
Conclusion
Selecting the right LLM comes down to aligning its latency characteristics with your specific workflow needs. For real-time applications like customer support, Mistral Large 2512 stands out with its 0.30-second TTFT, ensuring smooth and responsive interactions. On the other hand, GPT-5.2 strikes a balance between generating content and performing detailed analyses. If your focus is on batch processing where initial delays are less critical, Grok 4.1 Fast Reasoning delivers impressive throughput once generation begins.
Models with faster initial response times are best suited for real-time scenarios, while those with higher sustained speeds shine in batch operations. Deciding between immediate feedback and overall completion time is key to finding the right fit for your application.
Efficiency doesn’t stop at model selection – prompt design plays a crucial role, too. Prompt engineering significantly impacts latency. Lengthy prompts increase token counts, which slows both the TTFT and output generation. By designing concise and focused prompts, even slower models can deliver faster and more reliable results.
For those looking to refine their prompts, God of Prompt offers a library of over 30,000 optimized prompts, along with guides tailored for platforms like ChatGPT, Claude, Gemini, and Grok. These resources help streamline instructions, cutting down on redundant inputs and unnecessary processing.
Additionally, techniques like streaming API calls and retrieval-augmented generation can slash latency times – from 50 seconds to under 10 seconds, achieving a 5x improvement. With tools like God of Prompt’s no-code automation bundles and prompt engineering guides, you can implement these optimizations without needing advanced technical skills. By combining thoughtful model selection with efficient prompt design, you can ensure faster performance and an enhanced user experience.
FAQs
What should I consider when selecting a large language model (LLM) for my use case?
When you’re choosing a large language model (LLM), it’s important to weigh factors like latency, performance, and cost. If you’re working on real-time applications – think customer support or live chat – quick response times are key to keeping the experience smooth. Pay close attention to metrics like first-token latency and per-token latency to make sure the model can deliver the speed you need.
Also, check for infrastructure compatibility. Some models are designed to work better with specific hardware setups or cloud platforms. Balancing latency, throughput, and cost is crucial to getting the best performance while staying within your budget. Benchmarking reports and performance comparisons can be incredibly helpful in narrowing down your options. In the end, the goal is to pick an LLM that aligns perfectly with your application’s needs and technical requirements.
How does the length of a prompt impact LLM speed and performance?
The length of a prompt directly impacts how quickly and efficiently large language models (LLMs) operate. Longer prompts demand more computational resources, which can slow down response times. This delay becomes especially noticeable in real-time scenarios, such as chatbots or voice assistants, where even small lags can disrupt the user experience.
To address this, prompt engineering focuses on refining and shortening prompts without compromising the quality of the output. By keeping prompts concise, you can achieve faster responses – an essential factor for tasks like customer support or high-traffic workflows. Effectively managing prompt length ensures smoother and more responsive interactions in LLM-powered systems.
What is the best large language model (LLM) for real-time customer support?
For real-time customer assistance, Claude Sonnet 4.5 from Amazon Bedrock stands out as a reliable option. It’s widely praised for its performance in customer support tasks, delivering responses with consistently low latency.
Thanks to its capability to manage fast-moving, dynamic conversations, it excels at providing prompt and precise answers in customer service situations.
Related Blog Posts
- Understanding the Real Cost of AI Agents
- Frameworks for GPT Benchmarking: Guide
- Domain-Specific GPTs vs Industry Benchmarks
- AI Monitoring Metrics: What to Track
Keep going: the prompt library has AI coding prompts and Claude prompts ready to copy and run.