AI Monitoring Metrics: What to Track



AI systems are only as good as their monitoring. Without tracking the right metrics, performance issues like model drift, hallucinations, and slow response times can quietly erode reliability and user satisfaction. This article breaks down the key metrics you need to monitor for effective AI performance management:
- Response Time and Latency: Measure how quickly your AI responds to user inputs. Delays over 1 second can frustrate users.
- Accuracy and Quality: Go beyond accuracy to track precision, recall, F1 scores, and text quality metrics like BLEU and ROUGE.
- Throughput and Scalability: Monitor request and token throughput to ensure your system handles growing demand.
- Business Impact: Link AI performance to outcomes like cost savings or increased revenue (e.g., AI-driven customer service saving $100M annually for Reddit).
To stay ahead, set thresholds, use real-time monitoring tools, and regularly review metrics. Proactive tracking ensures your AI remains reliable, efficient, and aligned with business goals.
Monitoring AI: Metrics, Observability & Production Quality Guide
sbb-itb-58f115e
Key Metrics to Track for AI Performance Monitoring
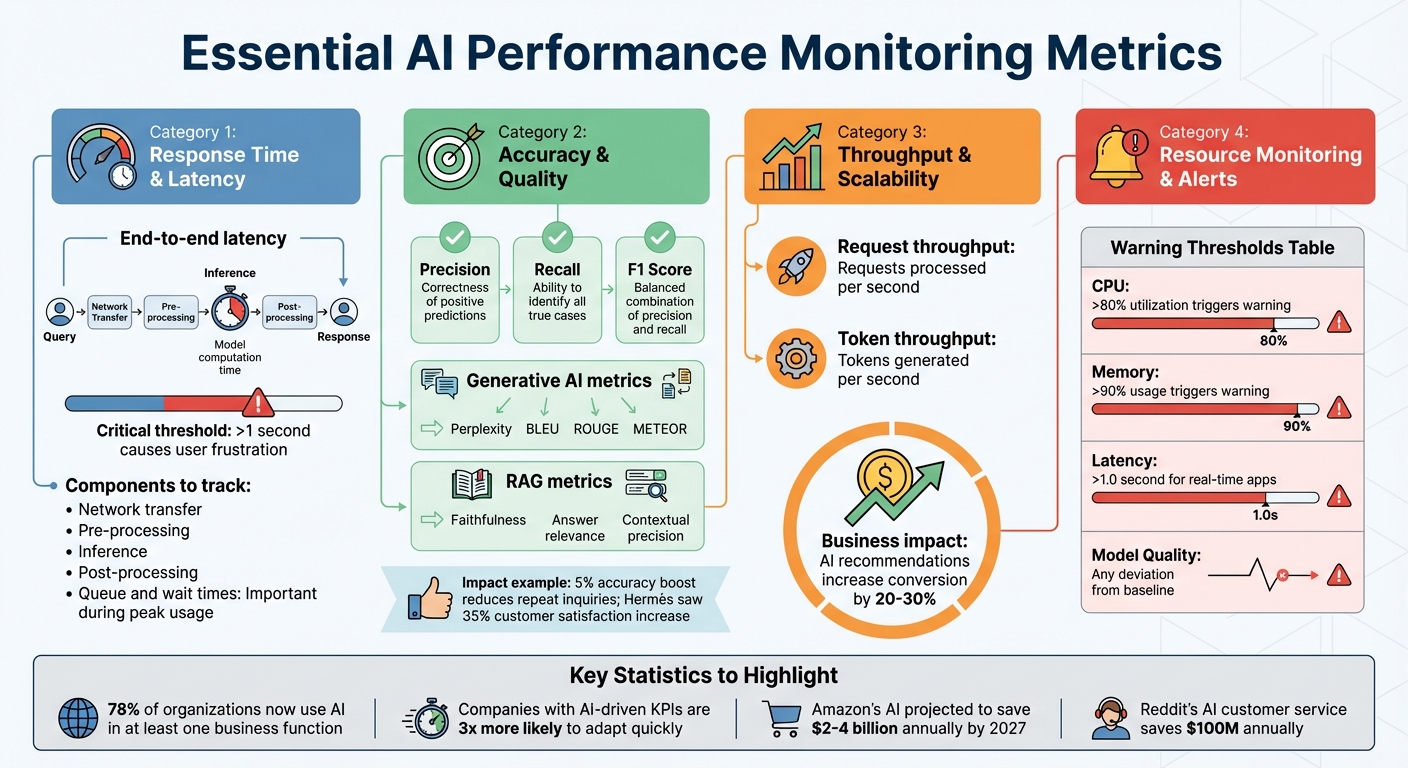
AI Performance Monitoring Metrics: Key Categories and Warning Thresholds
AI systems can be unpredictable, which makes keeping an eye on various metrics essential. Unlike traditional software, where uptime might be the main focus, AI performance monitoring requires a broader approach. You need to track metrics like response speed, quality, capacity, and business outcomes. Each of these provides a unique perspective on how well your AI is functioning in real-world scenarios, helping to avoid issues like model drift or system slowdowns.
The metrics you should prioritize depend on your specific use case. For example, a customer-facing chatbot must deliver lightning-fast responses - users expect answers in milliseconds, not seconds. On the other hand, a fraud detection system values accuracy and recall over speed, as catching fraudulent activity is more critical than processing time. Identifying the right metrics for your application ensures you can allocate resources effectively. Let’s break down some key performance categories.
Response Time and Latency Metrics
End-to-end latency captures the total time from when a user submits a query to when they receive a response, making it a critical measure of user experience for interactive applications. To identify bottlenecks, this metric can be broken down into smaller components, such as network transfer, pre-processing, inference, and post-processing times.
"Latency measures the time between submitting a prompt and receiving the complete response. This directly impacts user experience, especially for interactive applications where users expect responses in milliseconds, not seconds."
– Conor Bronsdon, Head of Developer Awareness, Galileo
Another important metric is model computation time, which evaluates the time it takes for the model to generate a response without factoring in network delays. During peak usage, metrics like queue and wait times become crucial for capacity planning and scaling decisions. Even hardware issues, like thermal throttling, can influence latency during real-time inferencing.
"Even a slight increase in latency can severely impact user experience or the effectiveness of automated systems."
– Somit Maloo, Technical Education Content Developer, Cisco
To improve latency, consider setting response time budgets based on your application’s needs. Techniques like response streaming can make long-form outputs feel faster, while caching frequently used queries can bypass the need for model inference altogether.
Accuracy and Quality Metrics
Relying solely on accuracy can be misleading, especially in scenarios like fraud detection. For instance, a model that labels every transaction as non-fraudulent might appear accurate but fails to deliver real value. Metrics like precision (the correctness of positive predictions) and recall (the ability to identify all true cases) are essential for a more complete picture.
The F1 Score combines precision and recall, offering a balanced way to evaluate overall model reliability. For generative AI, additional quality metrics come into play. Perplexity measures how fluently the model predicts text, while BLEU, ROUGE, and METEOR assess text quality, with METEOR also considering grammar and word order.
For Retrieval-Augmented Generation systems, metrics like faithfulness to source material, answer relevance, and contextual precision are critical. An emerging trend is using advanced models to evaluate outputs for subjective qualities like coherence and safety. However, human-in-the-loop evaluation remains unmatched for assessing creativity, tone, and empathy. To refine these qualitative outputs, you can turn your ChatGPT into an expert prompt engineer to ensure consistent quality.
Even small improvements in accuracy can have a big impact. A 5% boost in model accuracy can reduce repeat customer inquiries and improve satisfaction scores. For example, Hermès reported a 35% increase in customer satisfaction after launching its AI-driven chatbot in 2024. Similarly, Stitch Fix used AI to enhance personalization, boosting revenue per active client to $549 - a 3% year-over-year increase - even amid a shrinking client base.
Throughput and Scalability Metrics
Throughput metrics measure how well your system handles demand. Request throughput tracks the number of requests processed per second, while token throughput measures how many tokens the model generates per second. Monitoring these metrics helps ensure your infrastructure can scale as workloads grow. Staying ahead of demand ensures that user experiences remain smooth, even during spikes in activity. For instance, AI-powered recommendations have been shown to increase conversion rates by 20% to 30%.
User Engagement and Business Impact Metrics
Throughput and latency metrics are important, but the ultimate goal is to link AI performance to tangible business outcomes. Business metrics reveal how AI contributes to real-world success. For example, Amazon’s use of robotics and AI in its fulfillment centers is projected to save between $2 billion and $4 billion annually by 2027.
"AI metrics are where the guesswork of AI strategy meets scientific and operational rigor."
– Ian Heinig, Agentic AI Marketer, Sendbird
Combining quantitative metrics with qualitative feedback provides a well-rounded view of your AI’s performance. This approach ensures you can make timely adjustments before small issues grow into major problems.
Best Practices for Using AI Monitoring Metrics
Setting Thresholds and Alerts
Establishing clear thresholds for key metrics like accuracy, latency, and resource usage is essential. For instance, you might set a warning threshold when CPU usage exceeds 80% or memory usage surpasses 90%. It’s also helpful to implement detailed alerts for specific segments. For example, you could detect accuracy drops among specific customer groups or latency spikes in certain regions - issues that might go unnoticed if you only monitor overall system metrics. For generative AI applications, tracking Time to First Token (TTFT) is particularly important, as responsiveness can significantly impact user satisfaction.
Anomaly detection systems can be a game-changer here. By combining statistical models with machine learning, they can identify unusual patterns - like shifts in data distribution or a surge in low-confidence predictions. Automating responses to these alerts, such as triggering model rollbacks or retraining when thresholds are breached, ensures a swift reaction to potential issues. Additionally, having a formal incident management plan in place, with clearly defined roles and communication protocols, can streamline the response process.
| Resource Type | Key Metrics | Warning Levels |
|---|---|---|
| CPU | Utilization percentage, thread count | Over 80% usage |
| Memory | Available RAM, swap usage | Over 90% memory usage |
| Latency | Request-to-response time | Above 1.0 second (real-time apps) |
| Model Quality | Accuracy, Precision, Recall | Deviation from baseline |
Regularly revisiting these thresholds ensures they remain aligned with the evolving needs of your system.
Regularly Reviewing and Updating Metrics
AI systems thrive on consistent oversight. Establish a structured review cycle - for example, daily checks for operations, weekly reviews for trends, monthly evaluations for business impact, and quarterly assessments for strategic alignment.
As priorities shift, adapt your monitoring framework to stay relevant. A balanced scorecard with 4–6 well-defined indicators across areas like performance, business outcomes, safety, and user experience can help you cut through the noise and focus on what truly matters.
Periodic audits are also crucial. They ensure your monitoring practices meet performance, compliance, and ethical standards. Feedback from users, domain experts, and compliance teams can further refine your metrics. To measure the impact of any AI tool deployment, log key metrics - such as cycle time or defect rate - before implementation.
Using Tools for Real-Time Monitoring
Real-time monitoring tools are indispensable for gaining actionable insights. Integrate these tools into existing workflows for seamless operations. AI gateways like Gloo AI Gateway and kgateway are particularly useful for managing and monitoring interactions with AI models, tracking metrics such as request volume, latency, and security. Observability platforms like Lumenova AI and LogicMonitor offer unified dashboards that connect infrastructure health with model behavior and data quality.
"Monitoring tells you when performance changes. Observability tells you why." – LogicMonitor
Incorporate monitoring into CI/CD pipelines and adopt GitOps practices to detect performance degradation before it affects production. Unified dashboards can foster collaboration between data scientists and IT operations teams, simplifying root-cause analysis.
For anomaly detection, consider deploying Human-in-the-Loop (HITL) mechanisms to flag issues and guide retraining. If you’re working with prompt-based AI applications, tools like God of Prompt provide a library of over 30,000 AI prompts and guides for platforms like ChatGPT, Claude, Midjourney, and Gemini AI. These resources can help teams troubleshoot and optimize prompt performance for better AI interactions.
Challenges in AI Monitoring and How to Overcome Them
Balancing Performance and Cost Efficiency
AI systems are power-hungry, and the associated costs can spiral out of control if not carefully managed. Striking the right balance between delivering fast, accurate results and keeping infrastructure expenses in check is no small feat. For instance, newer GPU architectures like NVIDIA's Blackwell (B200/GB200) offer a 33–57% boost in training speed compared to the older Hopper (H100) generation, but these improvements come with a hefty price tag. It’s crucial to weigh the benefits of performance gains against the additional costs.
In conversational AI, token usage significantly impacts expenses. Every token processed adds to API fees and compute demands. To optimize costs, monitor metrics like Tokens Per Second (TPS) for efficiency and Time to First Token (TTFT) to maintain a smooth user experience. If you're using proprietary models like Gemini, much of the infrastructure management is handled for you, but you still need to keep an eye on API usage and token counts. On the other hand, self-hosted open models give you more control but require diligent tracking of GPU/TPU utilization, serving nodes, and storage to identify inefficiencies.
Set up automated alerts for resource spikes. For example, monitor HTTP 429 (Too Many Requests) errors, which indicate that your system has hit its capacity and needs scaling or optimization. Real-time dashboards showing compute usage can help you spot inefficiencies early, ensuring you’re handling more queries while keeping costs in check.
"You can't manage what you don't measure." – Hussain Chinoy and Amy Liu, Google Cloud
Next, let’s explore how to detect subtle performance issues that could undermine your system’s overall efficiency.
Detecting Small Performance Issues
Unlike traditional software, where failures are often binary (it works or it doesn’t), AI systems degrade gradually. This can lead to confidently incorrect outputs or subtle quality declines that may go unnoticed until users are already affected. Metrics like average response time can also be misleading since AI latency often fluctuates based on input complexity.
Two common culprits behind these issues are data drift and concept drift. Data drift happens when the statistical properties of input data change over time, while concept drift occurs when the relationship between inputs and outputs evolves. Both can erode accuracy, and without the right monitoring tools, these shifts are hard to catch. Real-time drift indicators, such as Wasserstein or Kullback-Leibler divergence, can help quantify these changes before they escalate.
Semantic monitoring is another essential strategy. Beyond tracking technical metrics, focus on whether outputs are meaningful and appropriate. Techniques like "LLM-as-a-judge" can automate quality scoring. Monitoring groundedness - ensuring responses are based on verifiable facts - can also help reduce hallucinations. Additionally, lineage tracking is invaluable. By mapping the entire workflow, from raw data inputs to the specific model version in use, you can quickly pinpoint the root cause of performance issues.
While performance monitoring is vital, ensuring data privacy and compliance is equally critical.
Ensuring Data Privacy and Compliance
Monitoring AI systems while staying compliant with privacy regulations is a complex challenge. Under the EU AI Act, violations can lead to fines as high as €35 million or 7% of annual global revenue. The Act will partially apply starting February 2, 2025, and be fully enforced by August 2, 2026. Even outside the EU, privacy concerns are universal, and users expect their data to be handled responsibly.
Start by implementing automated detection for Personally Identifiable Information (PII) and Protected Health Information (PHI) in both AI inputs and outputs. Use data anonymization and encryption protocols that align with standards like ISO 27001 or HITRUST. Deploy AI guardrails, such as content filters, bias detection, and moderation tools, to prevent non-compliant or harmful outputs. Explainable AI (XAI) techniques like SHAP or LIME can also be used to show how inputs influence decisions, which is essential for regulatory audits.
The shift from voluntary ethics to mandatory obligations in areas like fairness and privacy monitoring has raised the stakes. To stay ahead, establish strict access controls to limit who can view sensitive monitoring data, and configure automated compliance alerts to flag deviations from regulatory standards immediately.
"For compliance, legal, and governance teams, [AI metrics are] the foundation of AI transparency and trust, ensuring AI operates in a way that aligns with internal standards, regulatory frameworks, and societal responsibility." – Ian Heinig, Agentic AI Marketer, Sendbird
Conclusion: Optimizing AI Systems Through Effective Metrics
Keeping a close eye on AI systems isn't just a good idea - it's absolutely necessary. It’s the backbone of ensuring reliability and growth. Without clear metrics, you risk overlooking critical issues like model drift, hallucinations, or unexpected resource surges - problems that could negatively affect users before you even notice. With 78% of organizations now incorporating AI into at least one business function, success hinges on moving away from guesswork and embracing structured, data-driven evaluations.
The metrics we’ve discussed - such as time to first token, throughput, groundedness, and token usage - offer the insights needed to balance performance with cost control. Companies that incorporate AI-driven KPIs into their strategies are 3x more likely to adapt quickly and effectively. To stay ahead, focus on the right metrics, set flexible thresholds, and automate alerts to catch issues early. These practices not only fine-tune operations but also deliver measurable business outcomes.
We’ve seen how this works in practice. Take LinkedIn’s "AlerTiger" tool, for example. It uses deep learning to detect anomalies in machine learning models, ensuring features like "People You May Know" remain accurate even as user behavior shifts. Similarly, Netflix monitors feature drift and engagement metrics to retrain its recommendation models before users experience any drop in quality. These companies didn’t wait for problems to surface - they integrated monitoring into their workflows from the start. Their success highlights how proactive management of AI systems can lead to better outcomes.
To optimize your own AI workflows, consider tools like God of Prompt. With over 30,000 AI prompts and guides for platforms like ChatGPT, Claude, Midjourney, and Gemini AI, it simplifies prompt engineering best practices and minimizes token usage - one of the main culprits behind rising costs. By managing prompts effectively, you can cut down on token usage, improve response times, and keep your cost-per-request under control.
Set clear service level agreements (SLAs) for latency and accuracy, implement comprehensive tracing, and use automated safeguards to prevent low-quality outputs. As your system grows, continuously refine your monitoring approach to ensure your AI remains reliable, efficient, and aligned with your business objectives.
FAQs
What key metrics should I track to monitor AI performance effectively?
Monitoring AI performance effectively hinges on the system's purpose, but there are a few key metrics that universally matter: accuracy, efficiency, and reliability. Here's a closer look at some of the most important ones:
- Accuracy and success rate: This measures how frequently the AI delivers correct and relevant results, which is crucial for maintaining trust and usability.
- Latency: Tracks how quickly the system responds, ensuring a smooth and seamless user experience.
- Model drift: Keeps an eye on performance changes over time, helping to ensure the AI's outputs stay consistent and relevant.
- Resource utilization: Monitors how efficiently the system uses resources like CPU, memory, and energy, which can directly affect operational costs and scalability.
Keeping tabs on these metrics allows you to spot issues early, whether it's slower response times, declining accuracy, or inefficiencies. Addressing these promptly helps ensure your AI system stays reliable, effective, and aligned with your objectives.
What is the business impact of tracking AI monitoring metrics?
Tracking AI monitoring metrics is essential for ensuring that AI systems operate reliably and efficiently, directly contributing to business success. Key metrics like accuracy, latency, and resource utilization play a crucial role in spotting and addressing issues such as model drift or performance bottlenecks. By tackling these problems early, businesses can maintain smooth workflows, make informed decisions, and build stronger user trust.
Metrics like action success rates and user satisfaction also offer valuable insights that help businesses fine-tune their AI systems for real-world benefits. These include boosting productivity, cutting costs, and enhancing customer experiences. Regularly assessing these metrics allows organizations to improve their AI models, scale operations effectively, and align system performance with their broader goals - ultimately driving measurable results that support long-term success.
What are the best tools for monitoring AI performance in real time?
Keeping an eye on AI performance in real time means using tools that measure critical metrics like latency, accuracy, resource usage, and system health. Many platforms simplify this task by offering observability dashboards. For example, some tools are designed specifically for monitoring large language models (LLMs), evaluating their accuracy, throughput, and responsiveness.
There are also solutions that provide features like performance matrices to compare different models or integrations with alerting tools like Slack or PagerDuty to catch issues before they escalate. By combining these dashboards with real-time alerts and metric tracking, you can ensure your AI systems stay dependable and efficient.
Related Blog Posts
Loved by Business Owners





Based on 1K reviews
Get smarter on AI every week.
Ready to transform your business?