AI agents are transforming business operations by handling complex tasks like fraud detection and vendor security assessments through business automation. However, their unpredictable nature – producing varying results for the same input – makes traditional testing methods insufficient. To ensure reliable performance, businesses must adopt structured validation processes. Here’s how:
- Set clear goals: Define measurable success metrics like accuracy, efficiency, and reliability.
- Assess risks: Identify high-risk areas, such as tools with write access or sensitive data interactions.
- Test thoroughly: Use unit, functional, and multi-agent system testing to evaluate reasoning, outputs, and interactions. This is especially critical when deploying custom GPTs designed for specific departmental functions.
- Ensure compliance: Validate data handling against regulations like GDPR and HIPAA.
- Monitor and improve: Continuously track metrics, test updates, and retrain models to avoid performance drift.
Skipping proper validation can lead to errors, compliance issues, and financial losses. A systematic approach ensures AI agents deliver consistent, safe, and effective results.
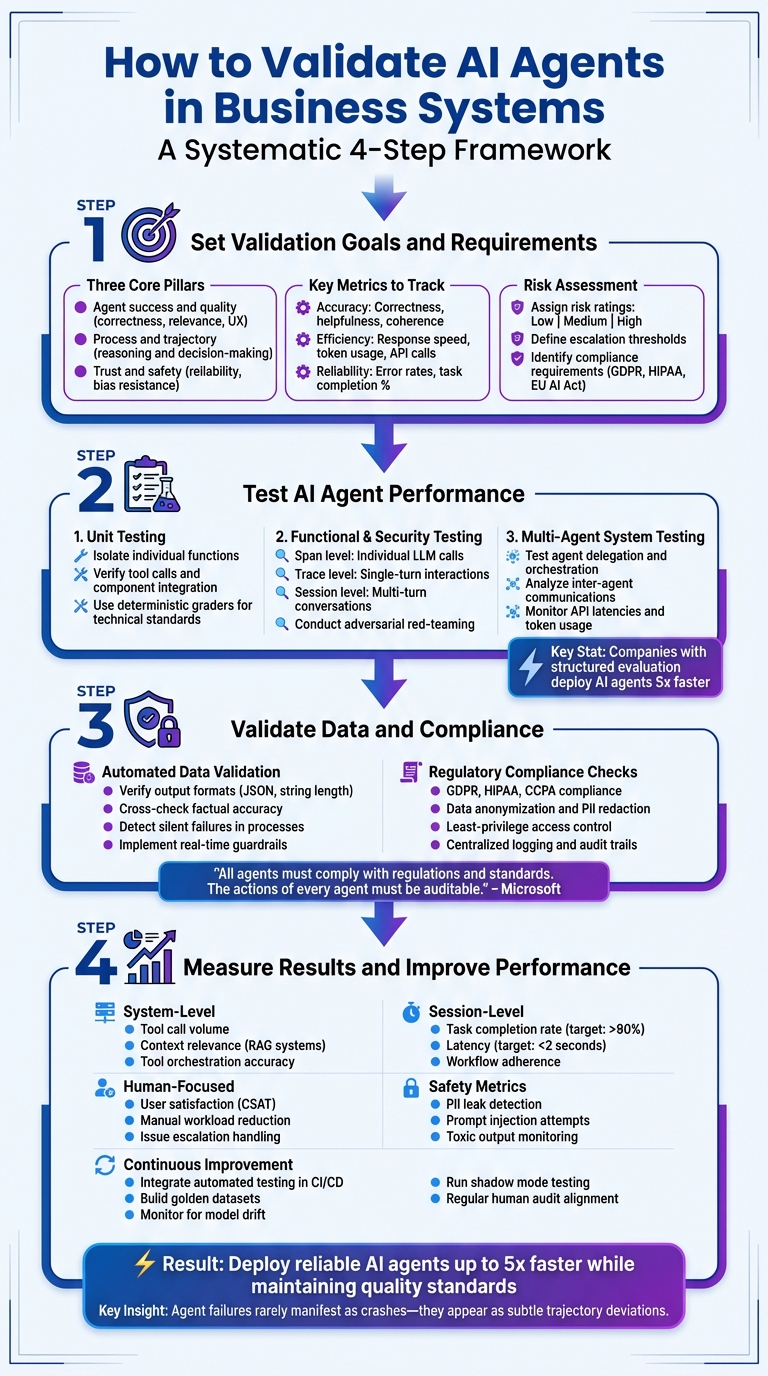
4-Step AI Agent Validation Framework for Business Systems
Evaluating and Debugging Non-Deterministic AI Agents
sbb-itb-58f115e
Step 1: Set Validation Goals and Requirements
Before diving into testing, it’s essential to define clear, measurable success criteria for your AI agent. Avoid vague objectives like "be helpful" and focus on specific, actionable goals such as "generate factually accurate summaries based on provided documents" or "successfully book multi-leg flights adhering to all user constraints". Without this clarity, it’s nearly impossible to determine if your AI agent is performing as intended. These well-defined criteria serve as the foundation for aligning your business goals with technical performance, as outlined in the following sections.
Define Business and Performance Goals
A strong validation framework rests on three core pillars that address what truly matters:
- Agent success and quality: Ensuring that outputs are correct, relevant, and provide a seamless user experience.
- Process and trajectory: Evaluating the internal reasoning and decision-making process to catch instances where the right outcome is achieved through flawed logic.
- Trust and safety: Measuring how reliably the system performs under challenging conditions, including resistance to bias and prompt injection.
From a business perspective, focus on outcomes like return on investment (ROI), increased productivity, cost savings, revenue growth, and customer satisfaction (CSAT). For functional performance, track metrics such as:
- Accuracy: Correctness, helpfulness, and coherence of responses.
- Efficiency: Speed of response, token usage, and API call counts.
- Reliability: Error rates and task completion percentages.
It’s worth noting that advanced large language model (LLM) evaluators often align with human preferences over 80% of the time, making them as consistent as human evaluators in many scenarios.
Identify Risks and Compliance Requirements
Understanding potential risks begins with pinpointing where nondeterminism enters your system – whether through user inputs, tool selection, or agent handoff points. By incorporating risk identification into your success criteria, you ensure your validation framework addresses both performance and compliance. Assign risk ratings (low, medium, high) to each tool the agent uses, considering factors like read-only versus write access, reversibility, and potential financial impact. For example, a tool authorizing refunds over $1,000 carries higher risk than one that simply retrieves order statuses.
"The reality is that when your agents are in production, they may be tested in unexpected ways, so it’s important to build trust that your agent can handle these situations." – Hugo Selbie, Staff Customer & Partner Solutions Engineer, Google
To address regulatory requirements, create a defensible process for assessing risk. Categorize use cases into risk tiers, such as those outlined by the EU AI Act. Clearly define escalation thresholds – for example, an agent should transfer control to a human after three failed attempts to understand user intent or when handling high-stakes actions. Use adversarial testing to uncover vulnerabilities by introducing messy data, typos, demographic variations, or prompt injection attacks.
Create a Validation Framework
A robust validation framework combines multiple evaluation methods across varying levels of detail. These include:
- Span level: Evaluating individual tool calls.
- Trace level: Reviewing single-turn interactions.
- Session level: Analyzing multi-turn conversations.
Your framework should incorporate a mix of evaluators:
- Deterministic checks for exact matches and schema validation.
- Statistical tools for detecting drift.
- LLM-based evaluation for subjective quality assessments.
- Human evaluations to set the gold standard.
Start with human evaluation to identify failure points, then translate these findings into binary pass/fail metrics for automated testing. Ensure that LLM-based judgments align with expert human evaluations before deploying automated scoring. Build golden datasets – human-validated input-output pairs – that act as benchmarks for performance assessment. Finally, weigh quality, cost, and latency to determine whether incremental quality improvements justify additional LLM calls. With this structured framework in place, you can confidently assess your AI agent’s performance.
Step 2: Test AI Agent Performance
After establishing a validation framework, the next step is to thoroughly test each component to ensure dependable performance within your business systems. With 82% of companies planning to integrate AI agents in business in the next one to three years, systematic performance testing is essential to avoid costly mistakes during implementation.
Unit Testing for Individual Functions
Unit testing focuses on isolating specific decision paths, tool calls, and component integrations to ensure that each part works as intended. This step verifies the independent functionality of modules, such as memory retrieval accuracy, planning logic, and proper action formatting. For example, deterministic graders (code-based checks) can confirm outputs meet technical standards like valid JSON formatting, string length, or regex compliance. Static analysis tools – like linters, type checkers, and security scanners (e.g., ruff, mypy, bandit) – help validate generated code or structured data.
A "shift-left" approach, which treats prompts as code, allows you to catch issues like hallucinations or logic errors early in the development process. For instance, Python-based functions can verify that an agent selects the correct API and provides the necessary parameters. Post-action inspections, such as checking whether a database record was created or a file exists, help confirm that actions were executed correctly.
"Scripts built for deterministic code simply ask, ‘Did this function run?’ – never, ‘Was it the right function to run right now?’"
– Conor Bronsdon, Head of Developer Awareness, Galileo AI
Since human QA typically spot-checks only 1–5% of interactions, automated unit tests are crucial for identifying rare but critical failures. Once a unit test passes, save it as a regression artifact to automatically validate future model or prompt updates.
From here, move on to functional and security testing to ensure processes are correct and data remains secure.
Functional and Security Testing
Functional testing examines whether the agent follows the correct process to achieve accurate outputs – not just whether the outputs themselves are correct. For example, an inventory reporting agent might produce accurate numbers but rely on outdated data, highlighting a process flaw.
"Metrics focused only on the final output are no longer enough for systems that make a sequence of decisions."
– Hugo Selbie, Staff Customer & Partner Solutions Engineer, Google
Evaluate functionality at three levels:
- Span level: Individual LLM calls or tool interactions.
- Trace level: Single-turn interactions.
- Session level: Multi-turn conversations to ensure context retention.
For subjective qualities like coherence and helpfulness, use an LLM-as-a-judge approach, where a secondary LLM scores the agent’s performance against human benchmarks. Companies with structured evaluation systems can deploy AI agents up to five times faster.
Security testing involves adversarial red-teaming to uncover vulnerabilities like prompt injection, data leaks, and bias. Create a "golden dataset" of ideal interactions, including specific tool calls and optimal responses, to serve as a baseline for regression testing. Simulate diverse conversational scenarios to identify the agent’s functional limits.
Multi-Agent System Testing
Once individual components are validated, test how multiple AI agents interact and manage tasks collectively. Ensure that a manager or orchestrator agent effectively delegates tasks to specialized sub-agents. Analyze inter-agent communications (the "chatter") to confirm instructions are clear and context is preserved. Multi-step workflows can be particularly error-prone; even with a 99% success rate per prompt, a four-prompt chain has an overall failure rate of approximately 4%.
Use distributed tracing tools to map execution paths across the agent hierarchy, making it easier to pinpoint where failures occur. Test intermediate responses – such as the natural language instructions exchanged between agents – to catch errors before they escalate into final output issues. AI-powered simulations can create hundreds of realistic interactions across different user personas, helping to ensure agents can handle varied scenarios. Additionally, monitor inter-agent API latencies and token usage to maintain both cost-efficiency and performance. Simulate component failures to assess whether the system can recover or degrade gracefully when a specialized agent encounters an issue.
Step 3: Validate Data and Compliance
Once performance testing is complete, the next step is to ensure AI agents handle data responsibly and meet all necessary regulations. This phase is crucial for avoiding violations and safeguarding sensitive information. As Microsoft emphasizes, "All agents must comply with regulations and standards", and "The actions of every agent must be auditable."
By following up on performance tests, these measures help maintain both data integrity and adherence to regulatory requirements. Let’s explore how automated validation and compliance checks strengthen your system’s reliability.
Automated Data Validation
Automated validation plays a key role in AI workflows by catching data errors before they disrupt business systems. Deterministic checks, for example, can confirm that outputs adhere to specific formats like valid JSON structures or correct string lengths. They can also cross-check factual accuracy against reference data.
"Generative AI is non-deterministic. Unlike traditional software, you cannot write a simple if statement to check correctness. You cannot fix what you cannot measure." – Qingyue (Annie) Wang, Google Codelabs
To ensure smooth operation, verify that agents follow proper action sequences – like authenticating users before accessing account data. This helps identify "silent failures", where outputs appear correct but stem from flawed processes.
Incorporating automated validation into your CI/CD pipeline acts as a quality checkpoint. For instance, if evaluation scores fall below a predefined threshold (e.g., an 80% trajectory match), the system can automatically fail the build. Real-time guardrails further enhance security by detecting issues like off-topic queries, jailbreak attempts, or the exposure of personally identifiable information (PII) before an agent responds. Routing all agent traffic through an AI gateway also enforces global token limits, centralized logging, and strict security policies.
Check Regulatory Compliance
While data validation focuses on internal accuracy, compliance checks address external regulatory risks. Make sure your agents comply with frameworks like GDPR, HIPAA, and CCPA. This involves enforcing data privacy principles – limiting agents to only the data they need, anonymizing personal details whenever possible, and respecting user rights such as data deletion. Automated tools can redact PII like emails, phone numbers, and payment information in logs and external communications.
Data residency is another critical factor. Identify where your data sources, agent runtimes, and output storage are located. Regular scans can detect configuration changes, while retention policies ensure logs are purged or anonymized after a set period.
To minimize risk, apply the principle of least-privilege access, granting agents only the data they need to function. JSON schemas can enforce strict rules for keys, types, and value ranges, preventing malformed data from entering your systems. Additionally, separating internal business data from public-facing agents – using either physical or logical boundaries – reduces the chance of accidental exposure.
Simulating real-world threats through adversarial testing, like prompt injections or data leaks, can uncover vulnerabilities . Using an AI prompt generator can help create diverse test cases for these scenarios. For high-stakes actions such as financial transactions or permission changes, human oversight should be incorporated, especially when the model’s confidence level is low. Finally, assign unique identities to each agent and centralize logging of all actions, tool usage, and decision-making processes. This ensures transparency and makes every behavior traceable and auditable.
Step 4: Measure Results and Improve Performance
Once you’ve ensured your AI agents meet data integrity and compliance standards, the next step is to continuously monitor their performance. This ongoing evaluation helps catch problems early and ensures your agents consistently support your business objectives. A key part of this process is defining and tracking performance metrics to guide improvements.
Track Key Performance Metrics
Performance tracking should happen on two levels: system-wide and session-specific. For system efficiency, keep an eye on metrics like tool call volume. High volumes might signal that agents are stuck in repetitive searches or reasoning loops, which can disrupt workflows. On the session level, it’s critical to confirm that tasks are completed accurately and workflows are followed as intended.
If you’re using Retrieval-Augmented Generation (RAG) systems, pay close attention to context relevance and data accuracy to prevent inaccuracies or fabricated details. Additionally, tool orchestration metrics can reveal whether agents are selecting the right tools and constructing accurate inputs for their actions.
Equally important are human-focused metrics. These include measuring user satisfaction, tracking reductions in manual workload, and assessing how well agents handle issue escalation. Safety metrics are another critical area – monitor for risks like leaks of personally identifiable information (PII), prompt injection attempts, or toxic outputs to safeguard both your users and your business.
"Agent failures in production rarely manifest as crashes or 500 errors. Instead, they appear as subtle trajectory deviations." – Maxim AI
To set clear performance expectations, establish thresholds before deployment. For example, aim for over 90% task completion and keep latency under 2 seconds. Tools like distributed tracing (e.g., OpenTelemetry) can help pinpoint issues, such as failing tool calls, and streamline debugging.
Once these metrics are in place, integrate continuous testing to quickly address any deviations from expected performance.
Continuous Testing and Model Retraining
With your metrics and validation framework ready, the next step is to incorporate automated testing into your CI/CD pipeline. This ensures that every code update is evaluated against quality benchmarks, preventing regressions from reaching production.
Create a "golden dataset" from successful interactions and past error corrections to refine your training data continually. Monitor for model drift, which can occur due to shifts in user queries, changes in data distribution, or updates to upstream systems. Use these insights to trigger model retraining and fine-tuning as needed.
To test new agent versions without disrupting users, run them in "shadow mode" alongside live systems. This allows you to compare performance on real-world data in a safe environment. You can also simulate large-scale, multi-turn conversations by leveraging a second language model, which helps stress-test your agent under diverse scenarios.
Purpose-built evaluation models can speed up and reduce the cost of performance assessments. To maintain alignment with your business standards, regularly audit automated grading results against human expert reviews. This dual approach ensures your metrics remain accurate and meaningful for your objectives.
Conclusion
Validating AI agents is a critical process that helps avoid costly errors and ensures systems deliver measurable outcomes. By sticking to structured testing, verifying compliance, and committing to ongoing improvement, you create AI systems that not only perform well today but are also prepared to evolve and grow.
Organizations that adopt a systematic approach to evaluation and monitoring can deploy reliable AI agents up to five times faster, all while maintaining top-tier quality standards. This approach mitigates risks by catching issues like bias, hallucinations, or prompt injection early through advanced prompt engineering – before they can affect users. Additionally, building evaluation frameworks and context-specific datasets creates a strong competitive edge, making it harder for others to replicate your success.
"In a world where information is freely available across the world and expertise is democratized, your advantage hinges on how well your systems can execute inside your context." – OpenAI
Treating evaluation as a quality checkpoint within your CI/CD pipeline is essential. As outlined earlier, systematic testing and continuous evaluation are the backbone of reliable AI performance. Incorporating automated testing, monitoring for model drift, and refining golden datasets using top AI tools transforms business goals into clear, measurable requirements. This approach not only prevents setbacks but also turns every interaction into a chance to improve alignment and learn.
Start with well-defined success metrics, expand your testing strategy as agents mature, and find the right balance between accuracy, cost, and speed. The result is AI that consistently meets business needs while earning user trust through reliable, verifiable outputs.
FAQs
What are the steps to validate AI agents in business systems effectively?
Validating AI agents in business systems requires a structured approach to ensure they perform as expected and align with your organization’s goals. Start by setting specific objectives and clear success metrics. These could include the key tasks the AI agent needs to handle and measurable indicators to track its performance.
Next, develop test datasets and scenarios that closely resemble real-world conditions. This step helps you assess the agent’s decision-making abilities and the quality of its outputs in situations it’s likely to encounter.
Continuous monitoring is equally important. Keep an eye on how the agent behaves in production, analyze its performance over time, and gather feedback from users to pinpoint areas for improvement. To ensure reliability, test the agent against edge cases and challenging inputs – it’s a great way to see how well it handles unexpected situations.
By following a cycle of goal setting, testing, monitoring, and refining, you can establish a validation framework that ensures your AI agents operate effectively and safely in business environments.
How can businesses ensure their AI systems comply with regulations like GDPR and HIPAA?
To stay aligned with regulations like GDPR and HIPAA, businesses need to put robust governance and security measures in place. This means carefully managing training data to avoid exposing sensitive information, using privacy-focused tools to de-identify personal data, and setting up clear, enforceable policies for handling data and securing AI models.
It’s also crucial to regularly monitor and validate AI systems to ensure they stay compliant over time. Adding safeguards to prevent unauthorized access and reduce risks tied to sensitive data is another key step. By adopting these measures, businesses can create AI systems that respect user privacy, meet legal requirements, and uphold ethical standards.
What are the key metrics to evaluate the performance and reliability of AI agents in business systems?
To gauge how well AI agents perform and hold up in business systems, it’s important to keep an eye on several key metrics. Start with accuracy, action success rate, and time to resolution – these reveal how well the agent handles tasks and makes correct decisions. Metrics like user satisfaction, cost savings, and task outcomes offer a broader view of how the agent contributes to overall business goals.
Equally important are model drift and data drift, which measure how stable and consistent the AI remains over time. Operational metrics such as throughput and concurrency shed light on efficiency, while tracking human override rates and escalation rates ensures the AI operates under proper oversight and adheres to compliance standards. Together, these metrics provide a well-rounded picture of how the AI agent performs in practical, real-world conditions.