Key Metrics for Custom GPT Models


Custom GPT models are purpose-built for specific tasks, like summarizing documents or managing customer support, and require tailored evaluation metrics to measure their performance effectively. Unlike general-purpose GPTs, which are assessed using broad benchmarks, custom models prioritize business-specific goals such as accuracy, relevance, and compliance. Here’s what matters most:
- Accuracy: Focuses on matching outputs to domain-specific datasets. For example, receipt extraction models achieved up to 89% accuracy in tests.
- Faithfulness: Ensures outputs are verifiable and free from hallucinations, especially critical for Retrieval-Augmented Generation (RAG) systems.
- Task Completion: Measures success in achieving specific objectives, like summarization quality or instruction adherence.
- Instruction Following: Evaluates how well the model aligns with prompts, even when user inputs are unclear.
- Cost and Scalability: Custom models often have lower long-term costs but require more setup, while general-purpose models are easier to deploy but come with higher per-task costs.
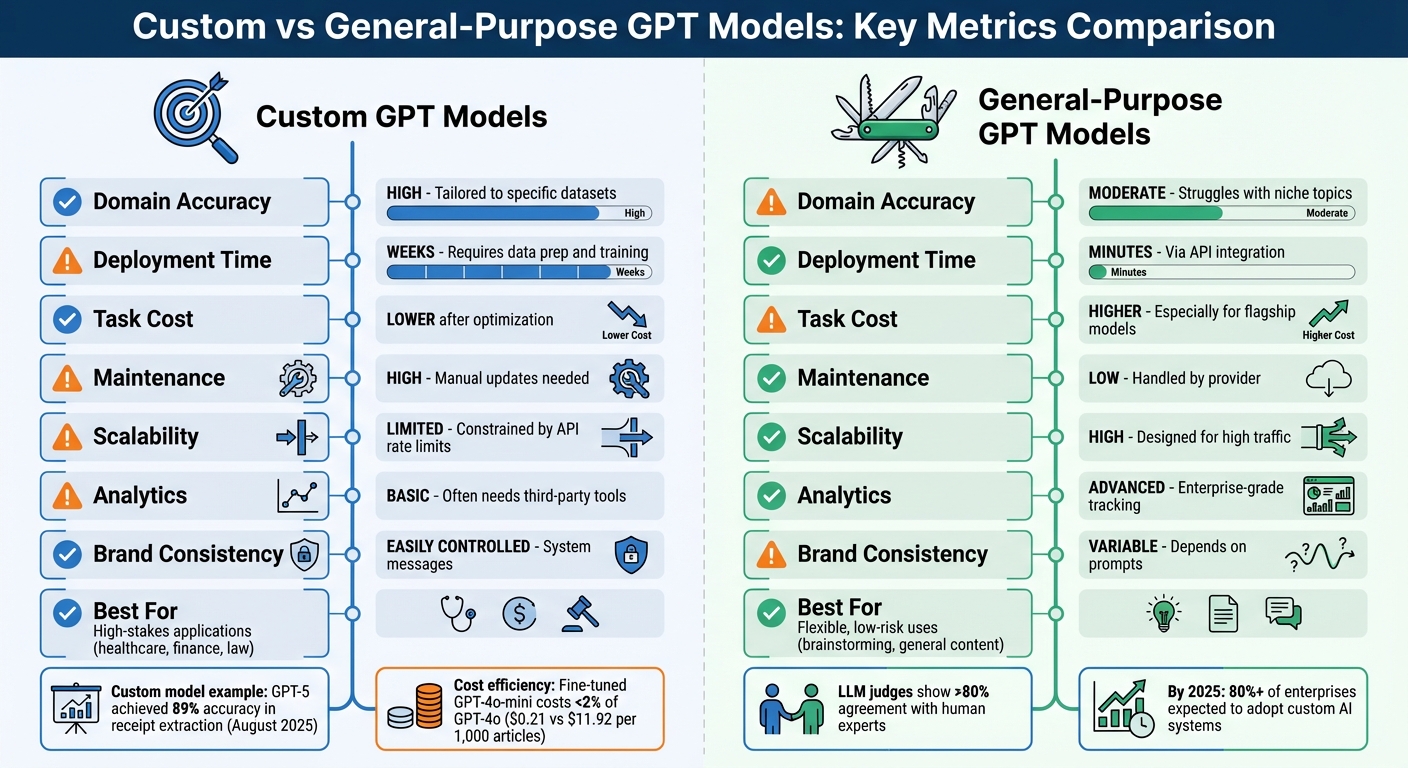
Quick Comparison
| Criteria | Custom GPT Models | General-Purpose GPT Models |
|---|---|---|
| Domain Accuracy | High; tailored to specific datasets | Moderate; struggles with niche topics |
| Deployment Time | Weeks; requires data prep | Minutes; ready via API integration |
| Task Cost | Lower after optimization | Higher, especially for flagship models |
| Scalability | Limited by API rate limits | Handles high traffic effortlessly |
| Maintenance | Manual updates | Managed by provider |
Custom models excel in delivering precision for specialized tasks, while general-purpose models offer flexibility for broader applications. Choose based on your business needs and priorities.
Custom vs General-Purpose GPT Models: Key Metrics Comparison
Custom GPTs: Fine-tuning of GenAI
sbb-itb-58f115e
1. Custom GPT Models
Creating custom GPT models means tailoring them to specific domains, which requires metrics that align closely with business goals. For example, if you're developing a model to extract data from receipts, you'll need a ground truth dataset - essentially a domain-specific, annotated standard - to measure its performance effectively [7, 13]. Below, we break down key evaluation dimensions: accuracy, faithfulness, and task completion.
Accuracy and Correctness
Accuracy for custom models is all about how well the generated tokens match those in the annotated validation dataset. For instance, if a model achieves 0.9 accuracy, it means 90% of its tokens align with the ground truth. In August 2025, HumanSignal tested receipt extraction models and found GPT-5-mini scored 87% accuracy, while GPT-5 reached 89%, making both strong candidates for production use.
In domain-specific tasks, functional correctness often outweighs raw token accuracy. Instead of focusing on word-for-word matches, the key question is whether the output accomplishes its intended purpose - like correctly identifying essential details from a receipt [7, 10]. To illustrate, in April 2023, a Kolena engineer tested five GPT models using 11,490 CNN-DailyMail articles. The results showed GPT-3.5 Turbo outperformed the smaller Ada model with a 22% higher BERT-F1 score and a 15% lower failure rate, maintaining consistent performance even as text length increased.
Relevance and Faithfulness
Faithfulness plays a critical role in preventing hallucinations by ensuring every claim in the model's output can be verified against the provided context [7, 10]. This is especially important for Retrieval-Augmented Generation (RAG) models, which pull information from domain-specific documents. Faithfulness evaluation involves two steps: extracting claims from the output and verifying each one against the source material.
Relevance, on the other hand, measures how well the model addresses the prompt. It penalizes outputs that are redundant or incomplete [7, 10]. For specialized applications, reference-free metrics are often used, focusing on how outputs compare to specific source documents rather than general knowledge bases.
Instruction Following and Task Completion
Instruction following ensures that the model adheres to system prompts, even when user inputs might conflict with its specialized task. Generative AI can be unpredictable, and traditional testing methods often fall short. However, advanced LLM judges like GPT-4.1 have shown an impressive ability to align with human preferences, achieving over 80% agreement with human evaluations - on par with the consistency between human experts.
Task completion metrics validate whether outputs meet specific objectives by being accurate, relevant, and comprehensive. For example, in summarization tasks, success is often measured by achieving a ROUGE-L score of at least 0.40 and a coherence score of 80% or more using tools like G-Eval. Microsoft Research also emphasizes the importance of testing models with real user traffic to capture nuanced, "human-like" cognitive abilities that standard benchmarks might miss. To ensure robust performance, it's recommended to conduct scoped tests - covering everything from normal use cases to adversarial scenarios like jailbreak attempts - throughout the development process, rather than waiting until deployment.
2. General-Purpose GPT Models
General-purpose GPT models are built to handle a wide variety of tasks without requiring domain-specific training. Unlike custom models that focus on narrow, specialized areas, these models are evaluated for their broader capabilities. Their performance is measured using standardized benchmarks, which highlight their versatility across multiple domains rather than honing in on specific expertise. This evaluation approach helps clarify how different metrics contribute to the success of such all-encompassing systems.
Accuracy and Correctness
To gauge baseline knowledge across a wide range of fields, general-purpose models are tested using benchmarks like the MMLU (Massive Multitask Language Understanding). This benchmark includes over 15,000 multiple-choice questions covering 57 subjects, ranging from high school-level topics to expert-level fields like mathematics and law. For more specialized reasoning, task-specific benchmarks are used, such as GSM8K for multi-step math problems, HumanEval for coding abilities, and TruthfulQA, which evaluates whether models avoid parroting common misconceptions through its 817-question dataset spanning 38 topics.
QAG scoring introduces a verification step where models answer yes/no questions to confirm whether their outputs align with established ground truths. For tasks demanding advanced reasoning, models often undergo Reinforcement Fine-Tuning (RFT), where expert evaluators refine the model’s ability to generate coherent, high-quality responses by reinforcing its reasoning process.
Relevance and Faithfulness
Faithfulness metrics ensure that the information provided by the model aligns with its source material, helping to reduce inaccuracies or hallucinated content. This becomes particularly important when models rely on external data. Tools like SelfCheckGPT take a novel approach by generating multiple outputs and comparing them for consistency - any significant differences often indicate hallucinations.
Relevance metrics, on the other hand, assess whether the model's responses are both informative and concise, avoiding unnecessary or redundant details. The G-Eval framework, which employs advanced models like GPT-4, evaluates outputs based on human-like criteria such as coherence and relevance, scoring them on a 1–5 scale. As Jeffrey Ip, Cofounder of Confident AI, explains:
"LLM-as-a-judge is the preferred way to compute LLM evaluation metrics... as it is able to take the full semantics of LLM outputs into account"
Instruction Following and Task Completion
A model's ability to follow instructions and complete tasks effectively is a critical measure of its usefulness. While general-purpose models are known for their linguistic quality and reasoning abilities, they can be sensitive to how instructions are phrased. Traditional metrics like BLEU and ROUGE, which focus on surface-level text similarities, often fail to capture deeper semantic meaning, showing only moderate alignment (correlations of 0.3–0.5) with human evaluations for creative tasks.
In cases where models act as agents, tool correctness metrics evaluate their ability to use external tools or functions accurately, ensuring proper arguments and outputs. As noted by Microsoft Research:
"The machine learning community needs to move beyond classical benchmarking via structured datasets and tasks, and that the evaluation of the capabilities and cognitive abilities of those new models have become much closer in essence to the task of evaluating those of a human rather than those of a narrow AI model"
Text Quality and Fluency
In addition to accuracy and task completion, text quality plays a significant role in evaluating general-purpose models. These models are typically strong in producing fluent, coherent, and grammatically correct text. Metrics like BERTScore and MoverScore, which use contextual embeddings, prioritize semantic alignment over simple word matching.
The G-Eval framework continues to set the standard for assessing subjective factors like tone or brand consistency. By employing chain-of-thought reasoning, it generates scores that align closely with human preferences. In scenarios where ground truth data isn’t available, tools like SelfCheckGPT analyze internal consistency across multiple outputs to detect hallucinations. While general-purpose models perform well across broad quality metrics, additional grounding techniques are often required to ensure the reliability needed for high-stakes applications.
Pros and Cons
Choosing between custom and general-purpose GPT models boils down to weighing domain expertise against versatility. Custom models shine in specialized fields where precision is critical. They’re trained on carefully selected datasets - think FAQs, manuals, or proprietary documents - which minimizes inaccuracies and ensures responses are rooted in verified data. These models are also better equipped to handle sensitive information, making them a strong choice for industries like healthcare or legal services. As Arooj Ejaz from CustomGPT.ai explains:
"A Custom GPT delivers higher accuracy and reduces the risk of hallucinations by concentrating on a focused scope."
This targeted capability sets them apart from general-purpose models, especially in scenarios requiring deep domain knowledge.
On the flip side, general-purpose models are the go-to for broader, more flexible applications. They’re ready to use right out of the box - no need for data preparation or training - and can tackle a wide range of tasks, from creative writing to basic coding. The provider manages infrastructure, updates, and security, which lightens the load on your team. However, these models often come with higher per-task costs and can struggle with consistency, sometimes requiring extra effort through prompt engineering to refine their tone.
Cost and Scalability Considerations
When it comes to cost, the picture changes with scale. A fine-tuned GPT-4o-mini, for example, can deliver performance on par with GPT-4o at a fraction of the cost - less than 2%. In a benchmark for fake news classification, the fine-tuned GPT-4o-mini achieved 91.5% accuracy at just $0.21 per 1,000 articles. Comparatively, GPT-4o in a few-shot setup cost $11.92 to reach the same accuracy. While these savings are compelling, they come with upfront costs for data labeling, organization, and machine learning expertise.
Scalability is another area where general-purpose models have the edge. They’re designed to handle massive concurrent traffic, while custom GPTs often hit API rate limits and offer limited analytics - typically only basic metrics like "total conversations." This lack of detailed reporting can hinder efforts to refine and improve the model over time. Security is also a point of differentiation: custom models can be more susceptible to prompt extraction attacks, where users manipulate the bot into revealing sensitive instructions. In contrast, general-purpose models benefit from standardized, provider-managed security measures.
Key Differences at a Glance
Here’s a quick comparison of how these two types of models stack up across key criteria:
| Evaluation Criteria | Custom GPT Models | General-Purpose GPT Models |
|---|---|---|
| Domain Accuracy | High; tailored to specific datasets | Moderate; prone to inaccuracies in niche topics |
| Deployment Time | Weeks (requires data prep and training) | Minutes (via API integration) |
| Task Cost | Lower after optimization | Higher, especially for flagship models |
| Maintenance | High; manual updates needed | Low; handled by the provider |
| Scalability | Limited by API rate limits | Designed for high traffic |
| Analytics | Basic; often needs third-party tools | Advanced; includes enterprise-grade tracking |
| Brand Consistency | Easily controlled with system messages | Variable; depends on prompts |
This breakdown highlights the trade-offs between precision and flexibility, making it easier to decide which model best suits your needs.
Conclusion
Deciding between custom and general-purpose GPT models comes down to how well the evaluation metrics align with your business goals. General-purpose models are assessed using broad benchmarks, which may not perform well in areas requiring creativity or nuance. On the other hand, custom models rely on tailored metrics that focus on specific needs, such as maintaining faithfulness to proprietary data, achieving the right tone, and adhering to compliance standards.
For low-risk, flexible uses - like brainstorming ideas or creating general content - general-purpose GPT models are a convenient option. They’re ready to use immediately, don’t require data preparation, and can handle a variety of tasks without extra training. However, when it comes to high-stakes fields like healthcare, finance, or law, custom models are the better choice. They provide the precision and compliance necessary for these critical applications - areas where generic benchmarks often fall short. In fact, by 2025, more than 80% of enterprises are expected to adopt AI systems tailored to their specific business processes, moving beyond one-size-fits-all solutions.
Custom models often utilize frameworks like "LLM-as-a-judge" (e.g., G-Eval), which show over 80% agreement with human experts and outperform traditional statistical metrics. This makes them particularly effective for complex tasks that require empathy or strict regulatory compliance. While general-purpose models prioritize metrics like user retention and engagement, custom models focus on outcomes like productivity improvements - reducing workflow times or boosting instruction adherence from 70% to 95% with targeted expert feedback.
FAQs
How do custom GPT models differ from general-purpose models?
Custom GPT models are fine-tuned with carefully selected datasets to handle specialized tasks with greater precision. This process ensures the model is aligned with the specific needs of a particular use case, whether it's for industry-focused workflows or highly niche applications.
On the other hand, general-purpose GPT models are trained on diverse data to be flexible across a wide range of tasks. While this makes them versatile, they often lack the precision required for more specialized demands. Custom models step in to fill this gap, delivering results that are both relevant and tailored to specific objectives.
How do custom GPT models deliver accurate and reliable outputs?
Custom GPT models become more precise and dependable through fine-tuning on datasets tailored to their specific purpose. By focusing on domain-specific language and context, these models produce outputs that align more closely with what users expect.
Developers assess the model's performance using key metrics like accuracy, which measures how well the generated tokens match the intended output, and loss, which indicates prediction errors during training. These metrics provide valuable insights, helping refine the model and improve its alignment with the provided data.
What should businesses consider when deciding between custom and general-purpose GPT models?
When choosing between custom GPT models and general-purpose GPT models, it’s essential to consider your business’s unique needs and the metrics that align with your goals.
Custom GPT models are fine-tuned using specialized datasets, making them a strong choice for highly specific applications. Their effectiveness is often evaluated using metrics like accuracy and loss, which indicate how well the model performs for the intended task. These models excel in scenarios where precision and reliability are non-negotiable - think revenue-critical workflows or tasks with strict performance requirements. By tailoring the model to meet specific KPIs, businesses can achieve outputs that closely match their operational needs.
In contrast, general-purpose GPT models offer flexibility and adaptability across a wide range of tasks. However, they might not deliver the level of precision required for niche or highly specialized use cases. To make the right decision, weigh your priorities - whether it’s accuracy, reliability, or scalability - and choose the model that best aligns with your objectives.
Related Blog Posts
Loved by Business Owners





Based on 1K reviews
Get smarter on AI every week.
Ready to transform your business?